How Connections are established: PostgreSQL is implemented using a simple “process per user” client/server model. In this model there is one client process connected to exactly one server process. As we do not know ahead of time how many connections will be made, we have to use a master process that spawns a new server process every time a connection is requested. This master process is called postgres and listens at a specified TCP/IP port for incoming connections. Whenever a request for a connection is detected the postgres process spawns a new server process. The server tasks communicate with each other using semaphores and shared memory to ensure data integrity throughout concurrent data access. Once a connection is established the client process can send a query to the backend (server). The query is transmitted using plain text, i.e., there is no parsing done in the frontend (client). The server parses the query, creates an execution plan, executes the plan and ...
Posts
PostgreSQL Reporting Tools(Pgbadger) Installation & Configuration
PgBadger: The PostgreSQL log analyzer “pgBadger” is an open source “fast PostgreSQL log analysis report” program written in Perl that takes the log output from a running PostgreSQL instance and processes it into an HTML file. The report it generates shows all information found in a nice and easy to read report format. These reports can help shed light on errors happening in the system, checkpoint behavior, vacuum behavior, trends, and other basic but crucial information for a PostgreSQL system. FEATURES: pgBadger reports everything about your SQL queries: Overall statistics. The most frequent waiting queries. Queries that waited the most. Queries generating the most temporary files. Queries generating the largest temporar...
PostgreSQL pg_pool-II Installation and Configuration
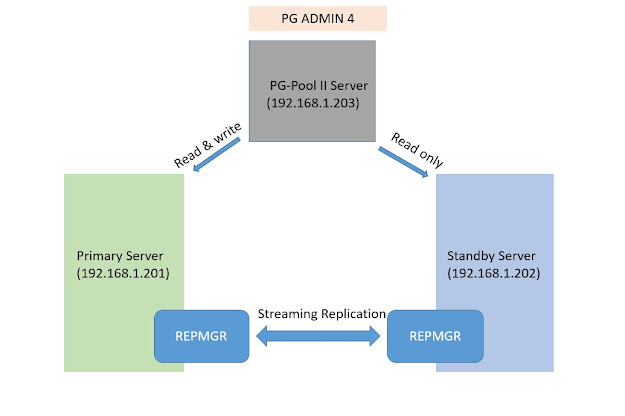
Pgpool-II Pgpool-II is a proxy software that sits between PostgreSQL servers and a PostgreSQL database client. It provides the following features: 1.Connection Pooling: Pgpool-II maintains established connections to the PostgreSQL servers, and reuses them whenever a new connection with the same properties (i.e. user name, database, protocol version, and other connection parameters if any) comes in. It reduces the connection overhead, and improves system's overall throughput. 2.Load Balancing: If a database is replicated (because running in either replication mode or master/slave mode), performing a SELECT query on any server will return the same result. Pgpool-II takes advantage of the replication feature in order to reduce the load on each PostgreSQL server. It does that by distributing SELECT queries among available servers, improving the system's overall throughput. In an ideal scenario, read performance could improve proportion...
PostgreSQL Lock Management
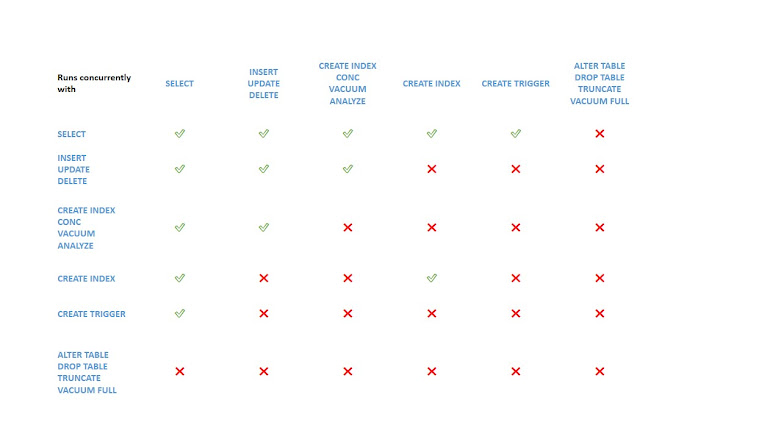
Lock: PostgreSQL provides various lock modes to control concurrent access to data in tables. These modes can be used for application-controlled locking in situations where MVCC does not give the desired behavior. Also, most PostgreSQL commands automatically acquire locks of appropriate modes to ensure that referenced tables are not dropped or modified in incompatible ways while the command executes. Types of Lock: Table-level Locks Row-level Locks Page-level Locks Deadlocks Advisory Locks 1.Table-level Locks: ACCESS SHARE: The SELECT command acquires a lock of this mode on referenced tables. In general, any query that only reads a table and does not modify it will acquire this lock mode. ROW SHARE: The SELECT FOR UPDATE and SELECT FOR SHARE commands acquire a lock of this mode on the target table(s) (in addition to ACCESS SHARE locks on any other tables that are referenced but not selected FOR UP...
PostgreSQL DB Link and FDW
DB Link: ‘DB Link’ in PostgreSQL enables a database user to access a table present on a different postgres instance. It provides a functionality in PostgreSQL similar to that of ‘DB Link’ in Oracle, ‘Linked Server’ in SQL Server and ‘Federated tables’ in MySQL. Options: dblink_connect — opens a persistent connection to a remote database dblink_disconnect — closes a persistent connection to a remote database dblink — executes a query in a remote database dblink_exec — executes a command in a remote database Example: postgres=# create extension dblink ; CREATE EXTENSION postgres=# create server myserver foreign data wrapper dblink_fdw OPTIONS (host'192.168.1.201',dbname'pearl',port'5432'); CREATE SERVER postgres=# create user MAPPING FOR postgres SERVER myserver OPTIONS (user'postgres',password'post'); CREATE USER MAPPING postgres=# select * from dblink('myserver','select * from emp') as a(id int,name text,age int); ...
PostgreSQL Vacuum Process
VACUUM: VACUUM reclaims storage occupied by dead tuples. In normal PostgreSQL operation, tuples that are deleted or obsoleted by an update are not physically removed from their table; they remain present until a VACUUM is done. Vacuum Options: 1.VACUUM: VACUUM simply reclaims space and makes it available for re-use. This form of the command can operate in parallel with normal reading and writing of the table, as an exclusive lock is not obtained. However, extra space is not returned to the operating system (in most cases); it's just kept available for re-use within the same table. Syntax: vacuum table_name; vacuum table_name (column_name); 2.FULL: Selects “full” vacuum, which can reclaim more space, but takes much longer and exclusively locks the table. This method also requires extra disk space, since it writes a new copy of the table and doesn't release the old copy until the operation is complete. ...
PostgreSQL Views and Materilized Views
View: A view is a database object that is of a stored query. A view can be accessed as a virtual table in PostgreSQL. In other words, a PostgreSQL view is a logical table that represents data of one or more underlying tables through a SELECT statement. CREATE OR REPLACE VIEW is similar, but if a view of the same name already exists, it is replaced. The new query must generate the same columns that were generated by the existing view query (that is, the same column names in the same order and with the same data types), but it may add additional columns to the end of the list. Updatable Views Simple views are automatically updatable: the system will allow INSERT, UPDATE and DELETE statements to be used on the view in the same way as on a regular table. A view is automatically updatable if it satisfies all of the following conditions: The view must have...
PostgreSQL Users/Roles and Privilages
Roles: PostgreSQL manages database access permissions using the concept of roles. A role can be thought of as either a database user, or a group of database users, depending on how the role is set up. Roles can own database objects (for example, tables and functions) and can assign privileges on those objects to other roles to control who has access to which objects. Furthermore, it is possible to grant membership in a role to another role, thus allowing the member role to use privileges assigned to another role. Role Attributes: CREATEDB NOCREATEDB CREATEROLE NOCREATEROLE LOGIN NOLOGIN SUPERUSER NOSUPERUSER INHERIT NOINHERIT BYPASSRLS NOBYPASSRLS...